My latest project was sort of a failure, but I’m going to post about it anyway, because such things are important.
For a recent event I wanted to create a unique way for people to LIKE something, and get a reward for it, so I grabbed a Raspberry Pi and got to work. The idea was pretty simple, a full screen display showing the number of Facebook likes, with the URL for people to visit the page (on their mobile devices) and like it. The display would then update in “near” real-time (Well, every 10 seconds) and there would also be a surprise…
Step #1 is always configuring the Raspberry Pi. I installed Raspbian, had it set to boot to the desktop, and installed the packages I needed, mainly Apache and Chromium, since I’d be using a local web server and web browser for the display.
Getting the Raspberry Pi to work as a kiosk display was next. I didn’t want any menus or OS parts showing, so I used Chromium running in kiosk mode. My /etc/xdg/lxsession/LXDE/autostart file looked like this:
# config to launch Chromium in kiosk mode and load our application
@xset s off
@xset -dpms
@xset s noblank
@chromium --kiosk --incognito http://127.0.0.1/likealot/
We got rid of the part that lets a screensaver run, and added in the bits to fire up Chromium in full-screen kiosk mode. (Oh, one note about Kiosk mode, it does not hide the mouse pointer, but we’ll deal with that later.)

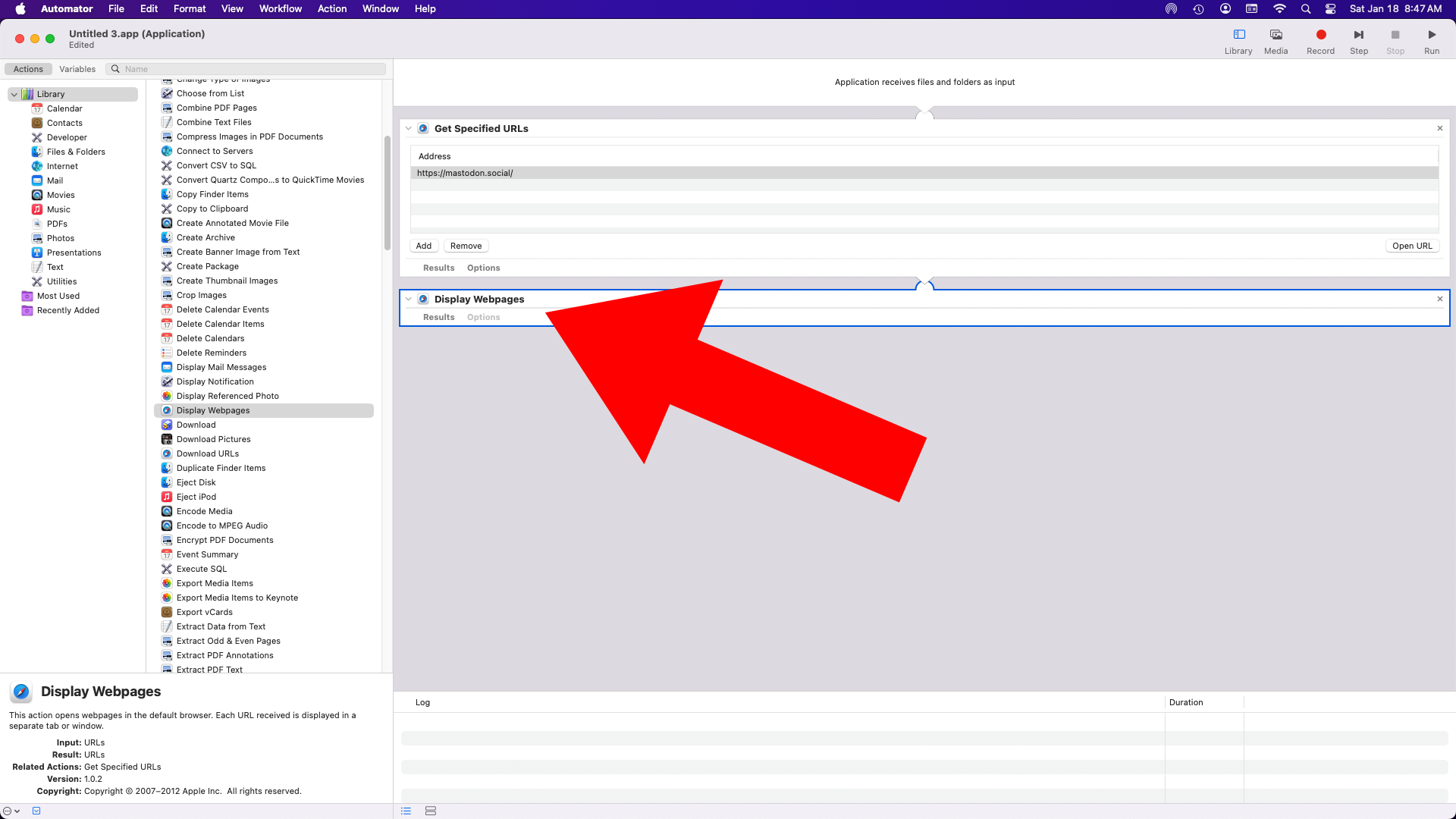
The results on the screen looked like this. Full screen, no browser or OS bits showing. I like this solution as it can be used for pretty much anything you can code up as a web page.
The display is set to refresh every 10 seconds, so it’s pretty up-to-date, and you’re really only limited by what you can display in a browser (Chromium) running on Linux (on a Raspberry Pi, in this case.)
As for the code, it’s less than 50 lines of Perl running as a CGI, and about a dozen lines of HTML in an HTML::Template file. There’s also a little CSS and an image.
Speaking of the CSS, it was the solution to hiding the mouse pointer for Chromium running in kiosk mode. I just added this bit:
/*
* using CSS to hide the pointer
*/
* { cursor: none !important }
For an informational kiosk you just want people to look at and not have to interact with using a mouse or keyboard, this solution works well.

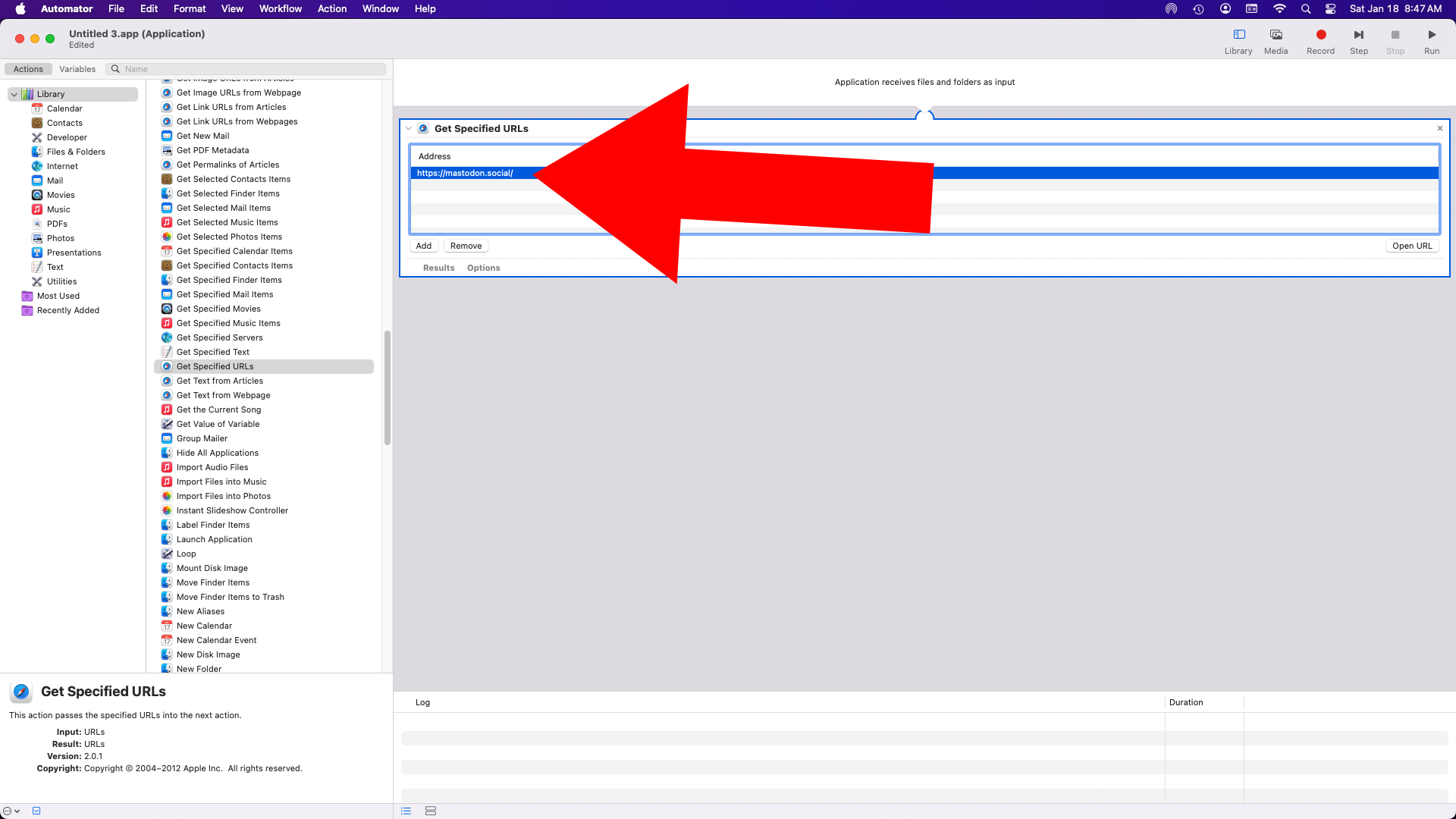
You might be saying “Hey! How do you get the number of likes!?” Well, you just ask JSON, or http://graph.facebook.com/?ids=z2marketing to be more precise. Facebook Graph API data holds the key, you just need the value.
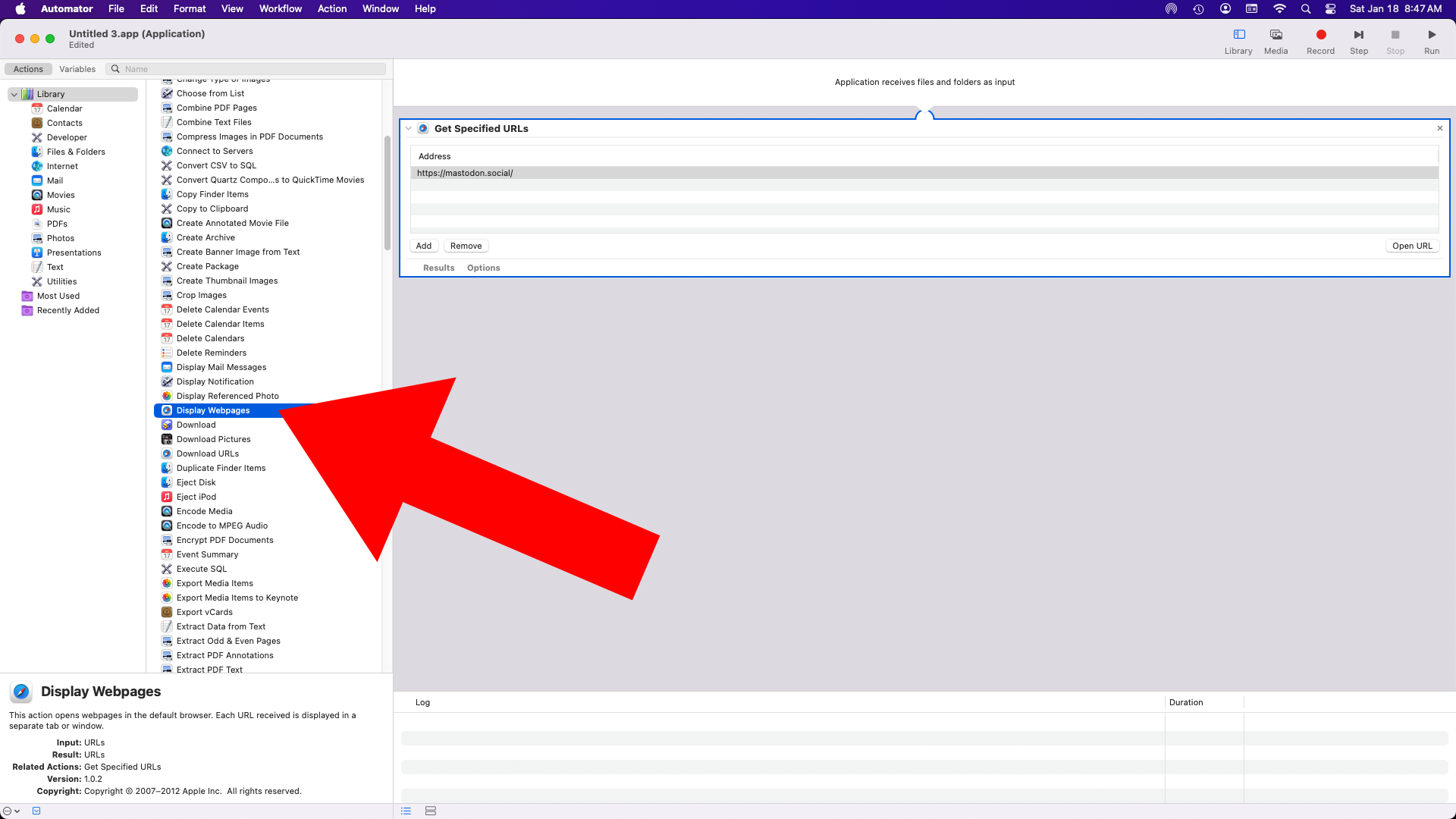
Oh, there was one more really fun bit! When someone liked the page and the page refreshed and the number increased, you’d hear applause!
The original idea was to just have the CGI do a system call to play the file using aplay. That did not work. I also tried mpg321 and that didn’t work. In the end I went the other way around and added… another Perl script! There’s a cron job that runs on startup, which launches a Perl script, which loops forever and looks at the counter file that the CGI uses. Every time the counter file changes (due to the CGI updating the number) the Perl script uses aplay to play the applause file.
The end result is pretty good. A person sees the display, goes to Facebook, likes the page, and within 10 seconds the display updates and you hear some applause!
I planned on making a sign or adding some text to entice people take action and get a “reward”. And of course the URL isn’t as helpful on a mobile device where you probably use an app instead of a browser, but this is all a good start.
Now, I mentioned a failure, so I should explain that part. For anything like this, where it needs to run for hours reliably and not just be a quick technology demo, you need some burn-in time. I had this running for a week with no issue. The first issue that came up was, what to do if you lose the Internet connection. (Hey, we use Time Warner, it happens!) You really don’t want to see a default Apache 500 error page, so the error page looked just like the main page, but with a message that said ‘Please stand by…”. That 500 page was set to redirect to the main page after 10 seconds, which would deal with occasional Internet or network outage situations. Since we were also using a WiFi connection with the Raspberry Pi, there’s always the chance of losing the WiFi connection. This didn’t seem to happen much, but it’s something you may need to deal with.
I also set Apache to not do any logging, as there’s really nothing valuable gained from logging after you’ve got everything running. It also helps to write less data to the SD card that holds the system because… corruption.
Oh yes, corruption! Every now and then I would reboot the system to make sure it would start up properly. It almost always did. Except when it didn’t. Once the Pi booted and there was a warning that the file system needed repair, so I repaired it, and all seemed well. I tested again for another week, and things seemed good. But then…
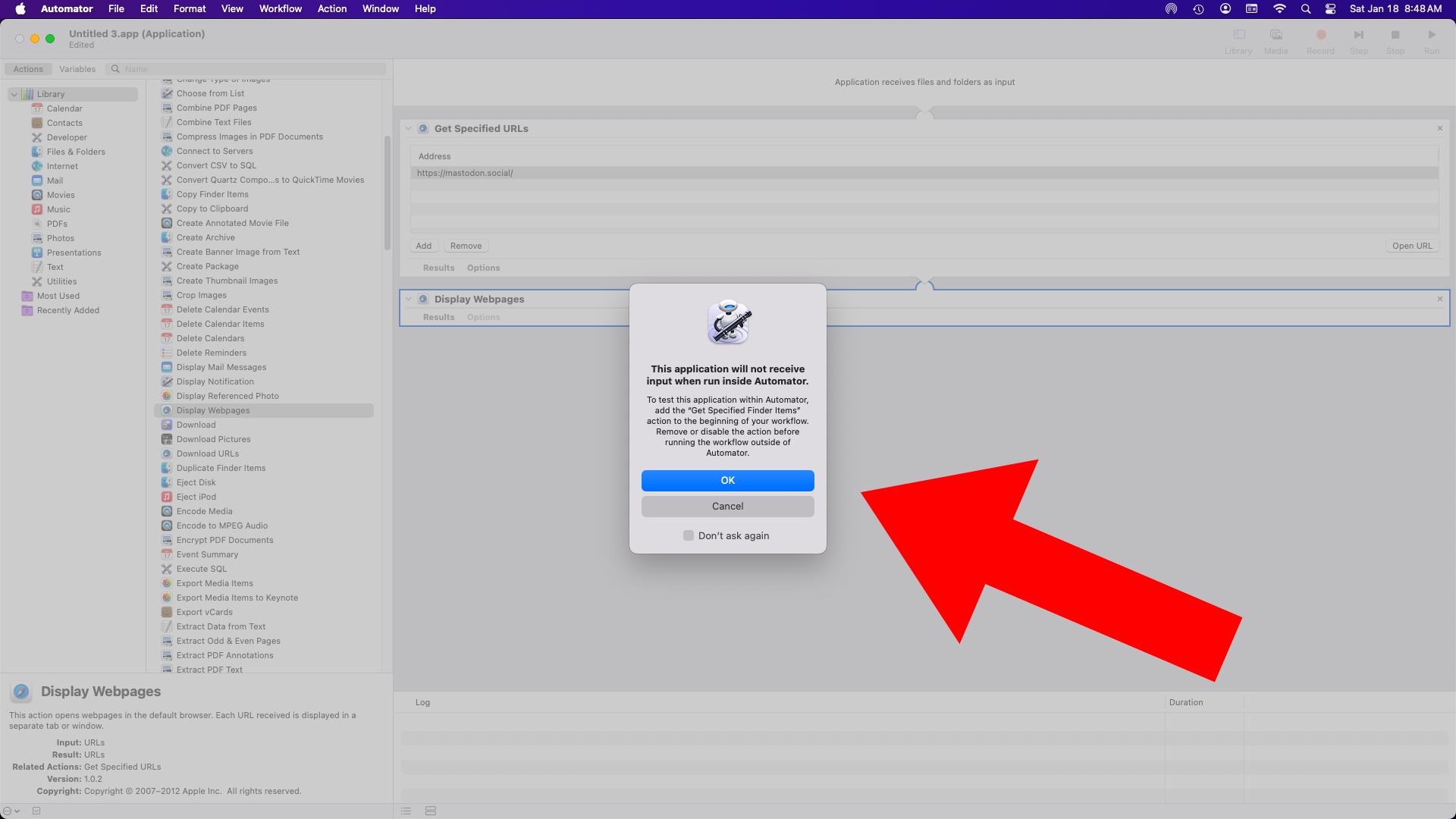
The day of the event, I had to move the system into place, and when I did that, and started it up, Linux would not boot. Even after 13 years I am still not enough of a Linux expert to fix every problem it throws at me, and I was stuck, and had a dozen other things to do, so it was dead.
I did the dozen other things and then ended up reinstalling Raspbian and trying to quickly reconfigure it, and get all my files in place, and got everything working except the audio… and the WiFi. There are a few tricks to getting audio working properly on the Raspberry Pi. I eventually got it working, but it was too late to deploy it. Oh well…
So next time, I will have a BACKUP SD card ready to put in place when the first one destroys itself. Or maybe I’ll just build two complete Raspberry Pi systems. Backups are good. Backups are good. Backups are good.
But don’t worry, I’ll take all the successful bits of this project and re-implement it in some other way in the future.