Back in Goodbye Google Search! I said:
“I think it’s our duty to find alternatives and try them out and see if we can move away from big tech, either by choosing self-hosted alternatives, more ethical companies, or ways to subvert the existing system.”
I also talked about quitting Google (Web) Search, or should I say Google AI Answers? Anyway, Google Web Search is dead, so it’s time for something else. I covered a bunch of options in the last post.
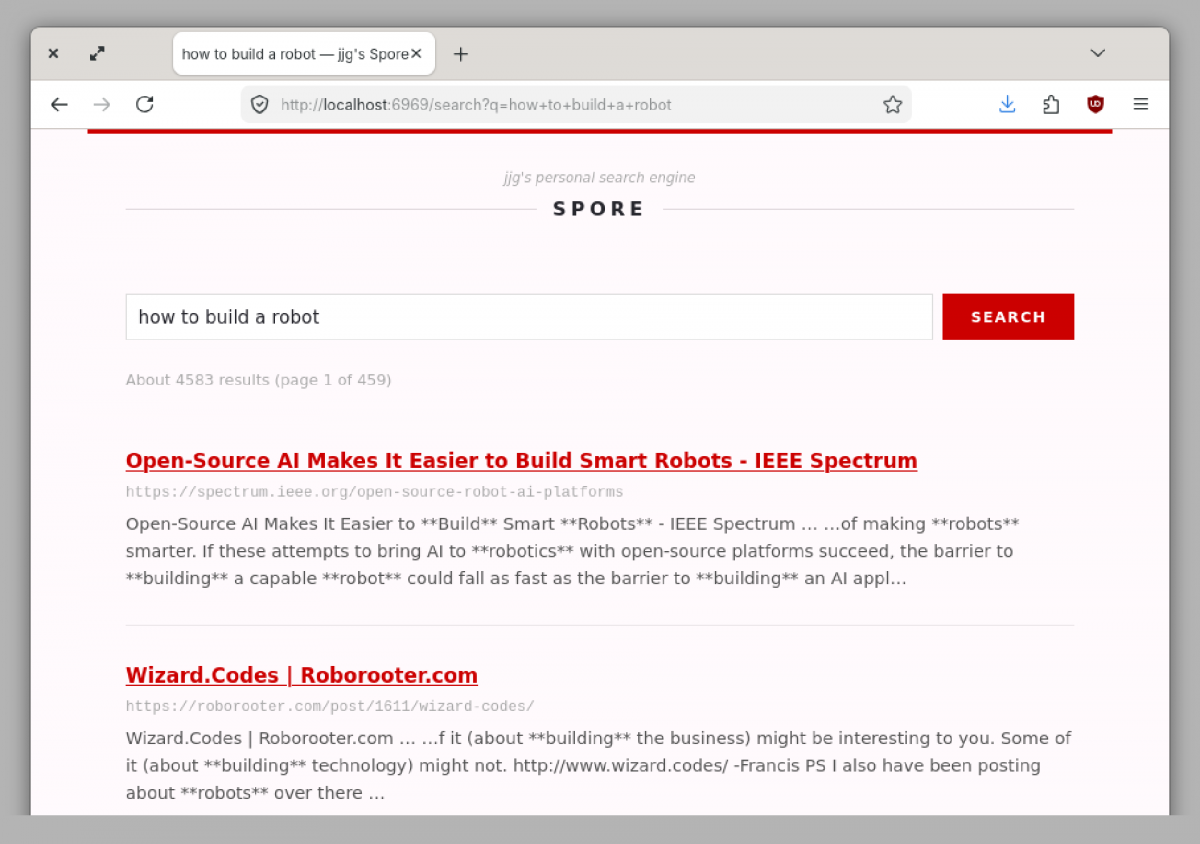
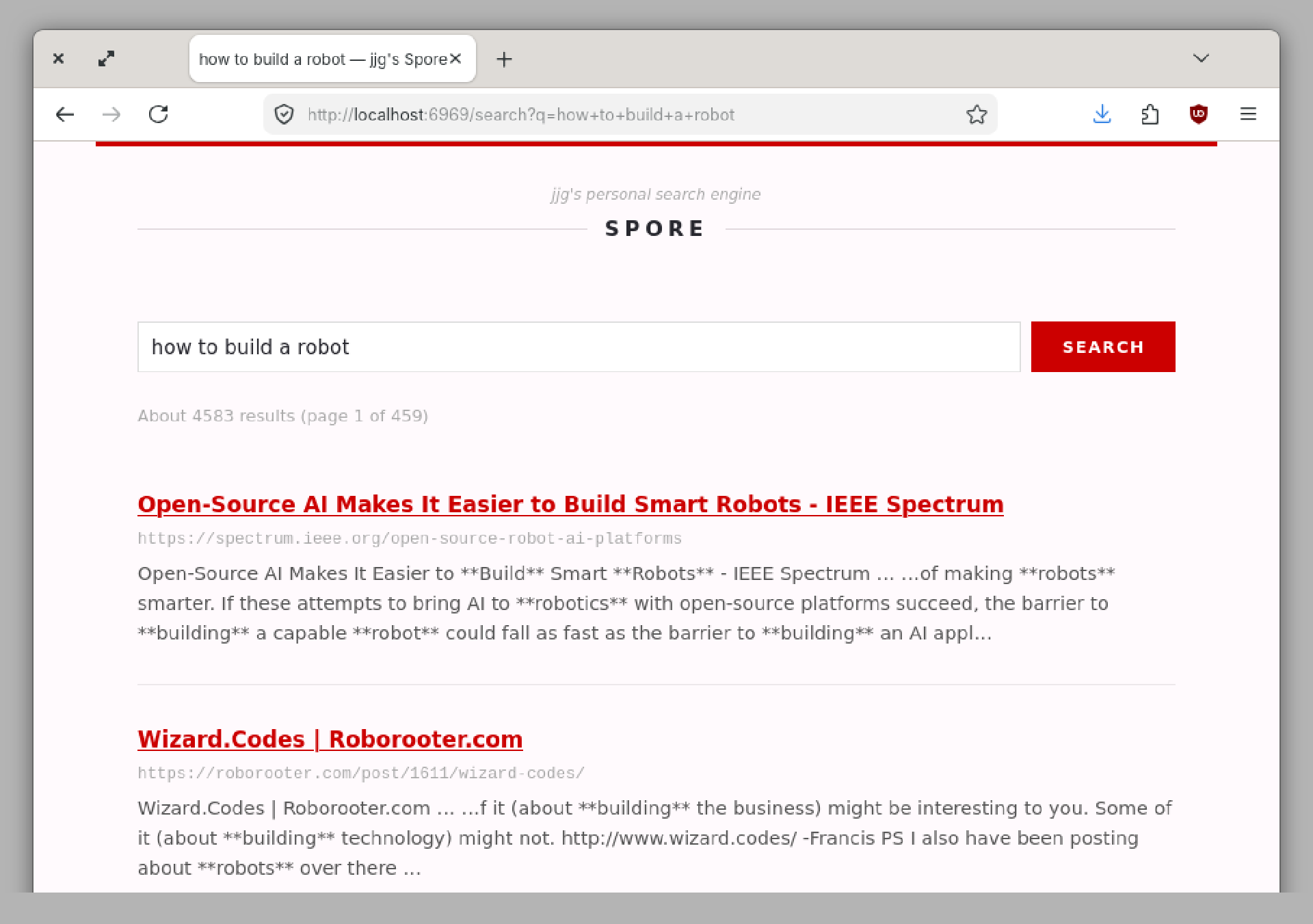
Meanwhile, through some discussions in a group chat I’m in with a few software developers the idea of a “Personal Search Engine” came up. I did a little looking around and there are things with that name, but they are often made to search your own documents locally stored, or web pages you have bookmarked, or they use LLMs (Yuk!) so this idea is more of a Personal Web Search Engine.
Now you need to go read Jason’s post: Personal Search Engines
A Personal Search Engine (PSE) is a search engine that specializes in your interests. It provides personalized search results by indexing only the things you are interested in, not by spying on you. Instead of crawling the entire Web and then looking for what you’ve searched for, A PSE crawls only the parts of the Web you are most interested in and looks for what you’re searching for there. The result is a list of hits that are relevant to your interests that point to websites you are more likely to know and trust.
I love this idea, and want to ramble on about it…
If I were to develop a PSE of my own, I think there are a few things I’d it to do.
Index Everything I Browse:
As I browse the web I’d like to just index every page I visit. This might seem like a lot of pages but honesty it’s probably less than feeding just one large domain to the index. If I am searching for some obscure thing like writing specific Arduino code to do some weird MIDI thing I may visit a dozen or more pages, and I’d like to see those all added to my index. Then the next time I need to find what I found I could just search my own index. Ideally I could “PageRank” my results in some way, either automagically using my PES to do so when I click a link…
Or maybe I could manually set the ranking on a page so it comes up higher in my searches. Should there be a way to manually rank things? Why not? It’s not like you can game your own system for profit or something, right?
Use the RSS Feeds:
I subscribe to a bunch of RSS feeds through my feed reader (FreshRSS and NetNewWire) and they provide some searching capabilities, but maybe we can feed those indexes into our master index so our PES can use it. Alternately we add RSS feeds to the PES directly so blogs and any site with a feed can be incrementally indexed over time.
So those are just two ideas I wanted to get out there… I will probably have more.
I think the magic of this is that while I mentioned SearXNG in the previous post, even though it’s a container application and was dead simple to install onto my NAS, it still relies on the indexes of other already existing search engines.
It’s 2026, and while we (still) have a number of options to search the general web, there is absolutely no reason we cannot self host our own personal web search engines.